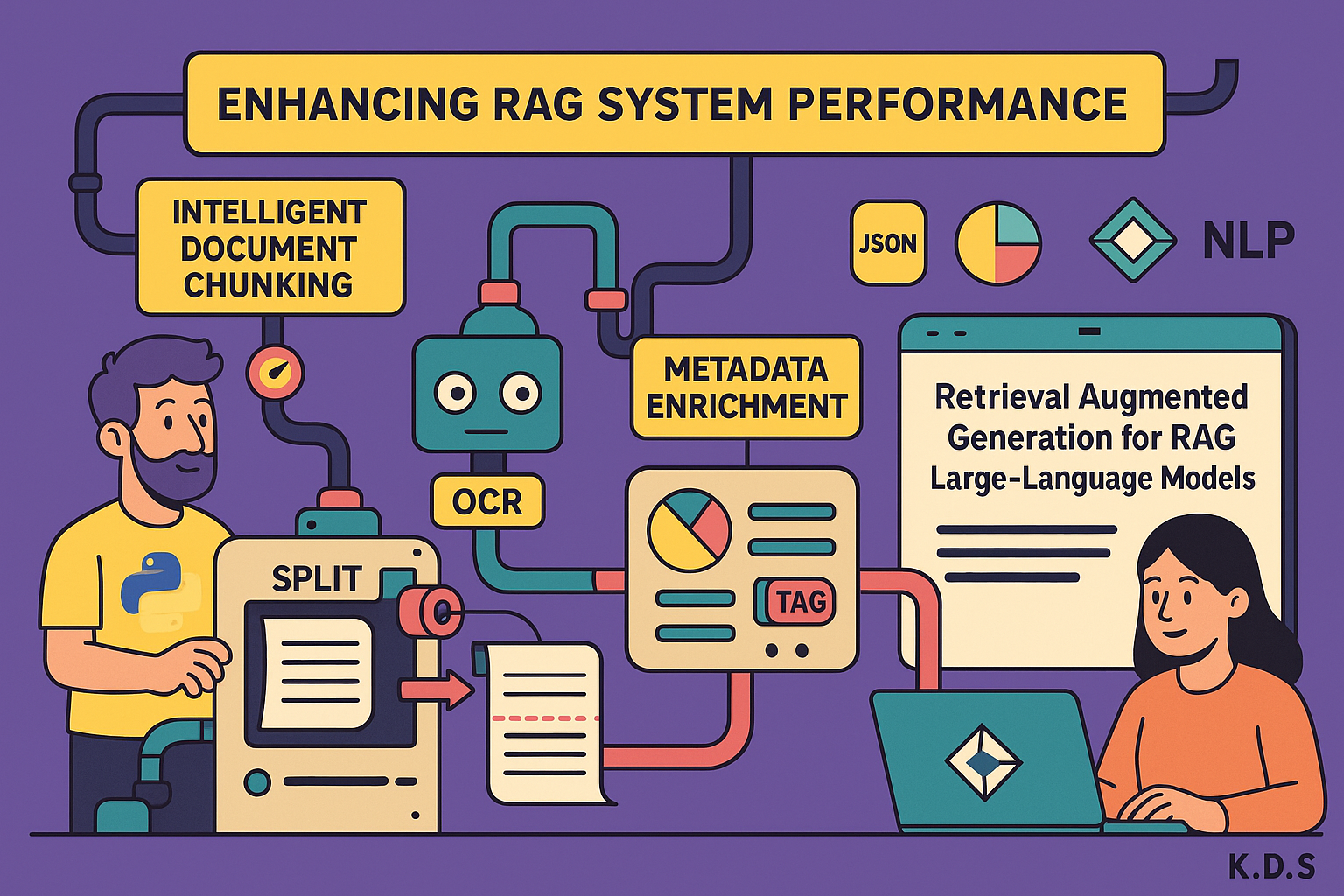
Retrieval Augmented Generation (RAG) systems are becoming increasingly vital for enhancing the capabilities of Large Language Models (LLMs) by providing them with relevant context. While foundational steps like ensuring clean documents and selecting an effective RAG method (e.g., hybrid search, graph-based) are crucial, there are advanced techniques that can significantly boost your system’s performance.
This article details three key strategies, independent of the specific RAG system used, that will drastically improve the quality of both document ingestion and retrieval.
Understanding RAG Fundamentals
Before diving into the tips, let’s briefly recall what RAG does. The primary goal of RAG is to intelligently add context to an LLM agent. LLMs have a limited context window (e.g., 120,000 to 128,000 tokens on average, with some models reaching 1 million). Since source documents are often longer than this window, RAG systems break them down into smaller chunks and store them in a vectorized database. Semantic search then intelligently retrieves relevant chunks based on a query.
Three Tips to Drastically Improve Your RAG System
Tip 1: Intelligent Document Chunking – Avoid Binary Ingestion
The first and most critical tip is to move beyond direct binary ingestion of your documents. Instead, focus on intelligent document segmentation.
When documents are ingested directly in binary format, tools often default to simple, unintelligent chunking. For example, a PDF splitter might cut documents based on a fixed character count (e.g., 800 characters) or basic line breaks (\n). This often leads to discontinuous and illogical chunks, where a single chunk might contain half a sentence or a mix of unrelated ideas, making semantic search less effective.
How to implement intelligent chunking:
- Prioritize Markdown conversion: Before chunking, convert your binary documents (like PDFs) into Markdown. Markdown’s structured nature (headings, lists, code blocks) provides inherent logical breakpoints.
- Enable Markdown-aware chunking: Many RAG frameworks offer options specifically designed to understand Markdown structure. Activate these options. When chunking, the system will then respect Markdown elements like headings, subheadings, and paragraphs, ensuring that chunks are semantically meaningful units. This means a chunk will likely start with a title or a complete thought, making it much more coherent for retrieval.
- Use
MapTime(or similar) options: Some tools provide features to improve chunk coherence during the splitting process. Ensure these are enabled to prevent arbitrary cuts within paragraphs or logical sections.
By doing this, you’ll dramatically reduce the number of disjointed chunks and significantly improve the quality of information retrieved for your LLM.
Tip 2: Leverage High-Quality Optical Character Recognition (OCR)
An often-overlooked yet crucial step for improving RAG systems, especially when dealing with scanned PDFs or images, is using a robust OCR (Optical Character Recognition) engine. OCR converts images of text into machine-readable text, and a good OCR is paramount for the success of intelligent chunking and overall data quality.
Why a good OCR matters:
- Accurate Text Extraction: A high-quality OCR ensures that the text extracted from your documents is accurate and free of errors. Poor OCR can introduce gibberish characters or misinterpret words, leading to irrelevant or misleading chunks even before chunking.
- Structure Preservation: Advanced OCR engines can often identify and preserve the structural elements of a document, such as paragraphs, headings, tables, and lists. This is critical for converting documents into structured formats like Markdown effectively. For instance, if an OCR can correctly identify a table, it can be converted into a Markdown table, which then makes it easier for the chunker to maintain its integrity.
- Improved Markdown Conversion: As discussed in Tip 1, converting documents to Markdown is vital. A good OCR facilitates this by providing cleaner and more structured text output, making the subsequent Markdown conversion process seamless and accurate.
How to implement a good OCR:
- Choose a capable OCR Solution: While some platforms offer built-in OCR, consider specialized OCR services if your documents are complex or varied.
- Integrate OCR into your workflow: Ensure that the OCR step precedes your Markdown conversion and chunking processes. The cleaner the input after OCR, the better the subsequent steps will perform.
By prioritizing accurate OCR, you lay a strong foundation for the entire RAG pipeline, ensuring that the text ingested is as clean and structured as possible.
Tip 3: Enrich Your Data with Meaningful Metadata
The third and perhaps most essential step is to enrich your ingested data with comprehensive metadata. Metadata acts as intelligent tags that provide additional context about each chunk, enabling more precise filtering and retrieval during the RAG process.
Why metadata is crucial:
- Granular Filtering: By storing relevant metadata alongside your document chunks, you can filter documents much more effectively during retrieval. This means that when a query is made, the system doesn’t just rely on semantic similarity but also on the specific attributes of the data it needs.
- Contextual Isolation: Metadata can be used to isolate conversations or user-specific data. For instance, if you have a platform where multiple users ingest documents, you can use a
session_IDoruser_IDas metadata. This ensures that when a user queries their agent, they only receive information from their own ingested documents, preventing data cross-contamination between users. - Categorization and Theming: You can assign metadata tags based on document categories (e.g., “marketing,” “HR,” “technical”), themes, or even document types. This allows the RAG system to retrieve chunks from a specific domain, enhancing relevance and reducing noise.
How to implement metadata enrichment:
- Identify Relevant Properties: During the ingestion phase, determine what metadata would be most useful for future retrieval. Common examples include:
session_ID/user_ID: For isolating user-specific data.document_type: e.g., “PDF,” “Web Page,” “Research Paper.”theme/domain: e.g., “Medical,” “Finance,” “Legal.”source: The original source or URL of the document.author/date: For specific document attributes.
- Add Metadata during Ingestion: When inserting chunks into your vectorized database, ensure that you attach these metadata properties to each chunk. Most RAG frameworks or vector databases provide options to include additional properties alongside the vector embeddings.
- Utilize Metadata for Filtering during Retrieval: In the retrieval phase, leverage these metadata filters. When the LLM agent makes a query, you can instruct the system to only search for chunks that match specific metadata criteria. For example, “Retrieve documents related to
marketingwith asession_IDmatching the current user.” - Allow Agent-Driven Filtering (Advanced): For more dynamic control, you can enable your agent to select metadata values. By integrating an “AI-driven” metadata selection mechanism, the LLM itself can determine which thematic area or session ID is most relevant to the user’s current query, further refining the retrieval process.
By diligently enriching your data with meaningful metadata, you empower your RAG system to perform highly precise and contextually relevant retrievals, leading to significantly better responses from your LLM agents.
Conclusion
Building an effective RAG system goes beyond basic setup. By implementing these three strategies—intelligent document chunking, leveraging high-quality OCR, and enriching data with meaningful metadata—you can drastically improve the precision, readability, and overall performance of your RAG pipeline, ensuring that your LLM agents deliver more accurate and relevant information.
🔍 Discover Kaptan Data Solutions — your partner for medical-physics data science & QA!
We're a French startup dedicated to building innovative web applications for medical physics, and quality assurance (QA).
Our mission: provide hospitals, cancer centers and dosimetry labs with powerful, intuitive and compliant tools that streamline beam-data acquisition, analysis and reporting.
🌐 Explore all our medical-physics services and tech updates
💻 Test our ready-to-use QA dashboards online
Our expertise covers:
🔬 Patient-specific dosimetry and image QA (EPID, portal dosimetry)
📈 Statistical Process Control (SPC) & anomaly detection for beam data
🤖 Automated QA workflows with n8n + AI agents (predictive maintenance)
📑 DICOM-RT / HL7 compliant reporting and audit trails
Leveraging advanced Python analytics and n8n orchestration, we help physicists automate routine QA, detect drifts early and generate regulatory-ready PDFs in one click.
Ready to boost treatment quality and uptime? Let’s discuss your linac challenges and design a tailor-made solution!
Get in touch to discuss your specific requirements and discover how our tailor-made solutions can help you unlock the value of your data, make informed decisions, and boost operational performance!
Comments