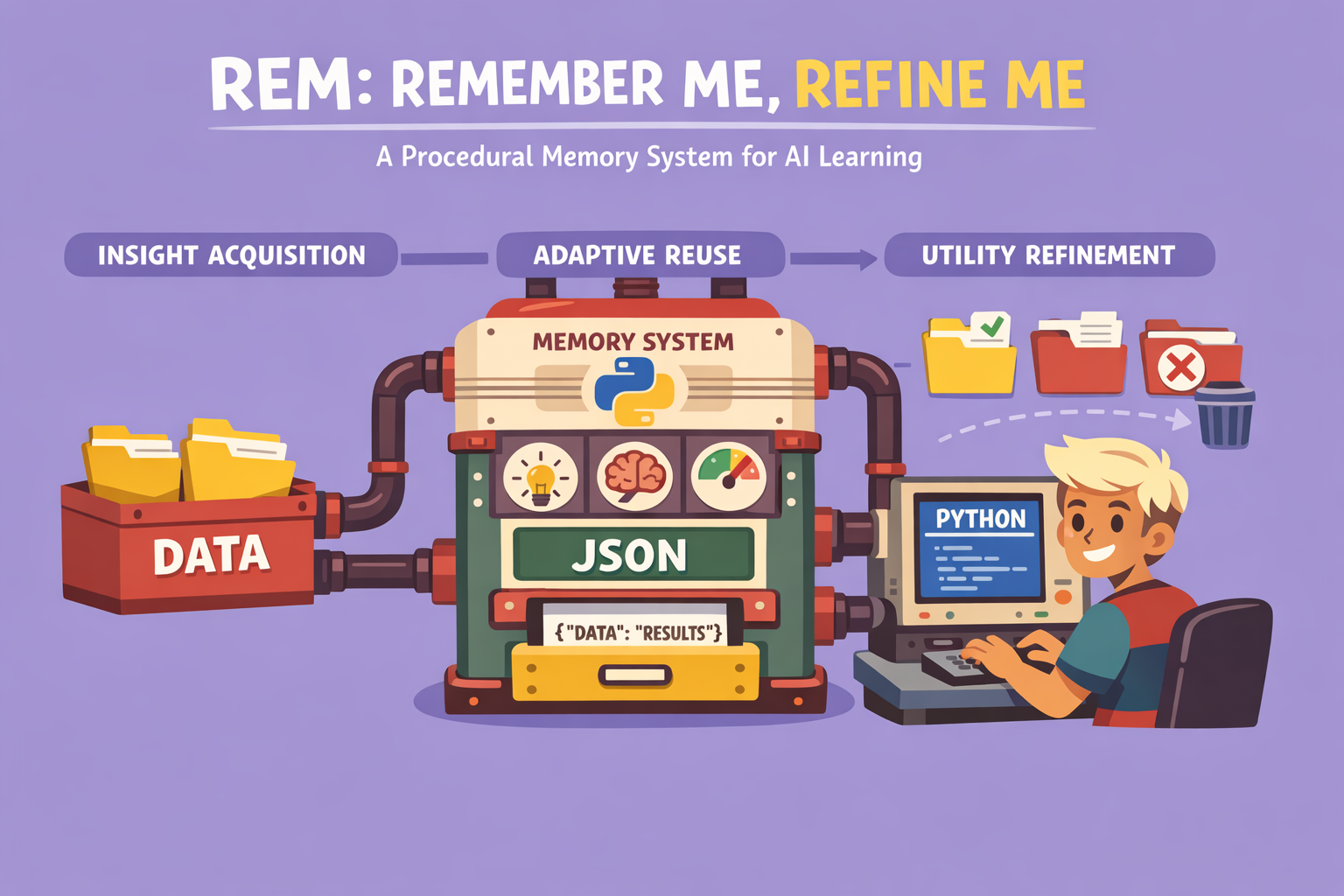
The field of AI is advancing at an unprecedented pace, with new research constantly emerging from around the globe. While much of the public attention often focuses on a few prominent figures and models, a significant portion of cutting-edge AI innovation, particularly in scientific documentation on platforms like Arxiv, originates from researchers in China. This article delves into one such groundbreaking paper, introducing the REM framework: Remember Me, Refine Me, a dynamic procedural memory system for AI agents that allows them to learn from their errors and adapt.
The Fundamental Problem with Current AI Agents
Traditional AI agents often suffer from a “passive accumulation” paradigm. They treat memory as a static archive, merely adding information without proper organization or refinement. Imagine an employee who diligently records every detail in a notebook but never reviews, edits, or discards outdated information. This leads to a cluttered, contradictory, and inefficient memory system.
Researchers have identified three key limitations in current AI agent memory systems:
- Coarse-grained Trajectory-Level Experiences: Agents store everything they do, not just what’s crucial. This creates excessive “noise” and makes it difficult to extract valuable lessons.
- Fetched Experiences Applied Without Adaptation: Agents blindly reuse old solutions without tailoring them to new contexts. This leads to inconsistent performance, as a solution that worked in one instance might fail in a subtly different scenario.
- Lack of Timely Update Strategies: Agents rarely clean up their memory, allowing irrelevant or outdated information to dilute important insights. This makes them deterministic even when dealing with probabilistic instructions.
A Practical Example: Stock Trading
Consider an AI agent tasked with buying 100 shares of Apple (AAPL) at market price.
- Without REM: The agent might invent a price (e.g., $190) based on past interactions, leading to a failed order if the actual market price is different (e.g., $227). Its memory simply records the failed attempt without learning why it failed.
- With REM: The agent, upon receiving the request, first calls a
get_stock_infotool to fetch the real-time market price for AAPL. Only then does it place the order using the correct price. If the task is successful, REM’s memory logs the rule: “When a user requests a market order without a specific price, always callget_stock_infobefore placing the order.” This learned rule enhances its future performance.
This example highlights how REM enables agents to learn and apply context-aware strategies, moving beyond simple rote memorization.
The Three Criteria For an Ideal Memory System
For an AI agent’s memory to be truly effective, it must meet these three ideal criteria:
- High-Quality Extraction: The system should extract reusable rules and principles from experiences, not just raw logs. It’s about distilling wisdom from data.
- Task-Grounded Adaptation: It must adapt past solutions to new contexts, understanding the nuances of how a previously successful approach might need tweaking for a similar but distinct task.
- Progressive Optimization: The system should continuously refine its memory, retaining what works and actively discarding what becomes obsolete, making sure the memory remains lean and relevant.
Think of it like a seasoned chef in Shenzhen who doesn’t just memorize recipes but understands the underlying principles of cooking. They learn from mistakes (e.g., “never add garlic to burning oil”), adapt their techniques to new dishes, and discard methods that no longer work, optimizing their craft over time.
The REM Framework: Remember Me, Refine Me
The REM framework operates on a continuous three-phase cycle: Acquisition, Reuse, and Refinement.
Phase 1: Experience Acquisition (Multifaceted Distillation)
Instead of passively storing everything, REM analyzes actions and extracts reusable rules.
How it Works:
- Trial Runs: The agent performs a task multiple times (e.g., 8 trials with different approaches).
- LLM Summarizer: A specialized Language Model (LLM) acts as a summarizer, analyzing these trials.
- Insight Extraction: The LLM extracts three types of insights:
- Success Pattern Recognition: What worked and why (e.g., “calling
get_stock_infobeforeplace_orderled to success”). - Failure Analysis: What failed and why (e.g., “inventing a price consistently led to failure”).
- Comparative Insight Generation: Key differences between successful and failed attempts (e.g., “verifying the price is crucial, guessing it leads to failure”).
- Success Pattern Recognition: What worked and why (e.g., “calling
Structure of a Stored Experience (E):
Each extracted experience is stored with a rich metadata structure:
- W (Usage Scenario): When to apply this experience.
- E (Experience Content): The rule or advice itself.
- K (Keywords): Tags for semantic retrieval.
- C (Confidence Score): How certain the system is about the validity of this experience (0 to 1).
- T (Tools Used): Which tools are involved in this experience.
Example for the Stock Trading Task:
- W: When a user wants to place a stock order without a precise price.
- E: First call
get_stock_infofor the real price, then use it inplace_order. - K:
stock,order,market,price,trading. - C: 0.85 (a high confidence).
- T:
get_stock_info,place_order.
Validation Steps:
Before archiving, new experiences undergo a validation process:
- LLM as a Judge: An LLM filters experiences.
- Rejection: If an experience is too vague or incorrect, it’s immediately discarded.
- Validation: Valid and useful experiences are prepared for archiving.
- Deduplication/Fusion: If a similar experience already exists, it’s either fused with the new one (if it adds new nuance) or replaced/discarded (if it’s a direct duplicate or inferior).
This process ensures that the memory is not only populated with relevant information but also constantly refined for quality and conciseness, akin to a diligent editor maintaining a knowledge base.
Phase 2: Experience Reuse (Context-Adaptive Reuse)
When the agent faces a new task, it intelligently searches for and adapts relevant past experiences.
The Pipeline:
- Recall: The system retrieves the top 5 (or a similar small number) experiences most similar to the current task. This involves transforming the task into a numerical embedding and comparing it to stored experience embeddings using cosine similarity – a high similarity angle means closer relevance.
- Rerank: An LLM then re-sorts these retrieved experiences based on their contextual relevance to the specific new task.
- Rewrite: Finally, the LLM reformulates the selected experiences to align perfectly with the specific requirements of the current task.
This dynamic retrieval and adaptation ensure that the agent isn’t just recalling information but actively applying it in a tailored, useful manner.
Phase 3: Experience Refinement (Utility-Based Refinement)
REM continuously cleans and optimizes its memory, adding valuable experiences and removing obsolete ones.
Selective Addition vs. Full Addition:
- Full Addition: Storing experiences from all trajectories (success + failure) yielded a lower performance (40.83% on a benchmark).
- Selective Addition: Storing only experiences from successful trajectories significantly improved performance (44.33%).
This indicates that isolated failed trajectories often lack sufficient context to provide meaningful lessons. Multiple failures together can be analyzed, but a single failure might lead to misleading conclusions. This also strongly suggests the benefit of using multiple LLMs and multi-model reasoning, allowing for comparison and validation of responses rather than relying on a single, potentially flawed output.
Conscious Reflection on Failures:
REM explicitly addresses failures through a structured loop:
- Initial Failure: An initial attempt fails.
- Failure Analysis: An LLM analyzes the reasons for the failure.
- Alternative Proposal: The system proposes a new strategy or correction.
- New Attempt: The agent retries the task with the corrected approach.
- Decision:
- Success: The validated lesson is stored in the dynamic, enriched memory. The experience gets recorded.
- Failure: The attempt is discarded to avoid polluting the memory. The system makes up to three re-attempts if the previous one failed, further refining before rejection or acceptance.
This iterative process of analysis, retrial, and selective storage is central to REM’s ability to learn robustly from errors.
Utility-Based Deletion:
Experiences are deleted based on a specific formula: an experience is removed if it has been retrieved at least 5 times and its success rate is below 50%. This prevents premature deletion of potentially important but rarely used experiences while ensuring that frequently used but ineffective ones are purged. This nuanced approach prevents memory pollution without losing critical, infrequent knowledge.
Experimental Results and Major Discovery (Memory Scaling Effect)
The researchers benchmarked REM’s performance against traditional memory systems using two demanding tests:
- BFCL V3: A function-calling test requiring agents to call the correct functions with precise parameters (150 tasks).
- Appwor: A simulation involving 9 daily applications (email, Spotify, etc.) and 457 APIs (168 tasks).
The results, using metrics like AVG@4 (average success rate over 4 independent trials) and Pass@4 (probability of at least one success over 4 trials), were compelling. (Four trials are used because LLMs are non-deterministic, and multiple trials provide a more reliable measure).
On a smaller model (e.g., Qwen 3B-8B parameters):
- Without memory: ~27% AVG@4
- With REM: ~34% AVG@4 (a significant gain of over 7 percentage points)
On a medium model (e.g., Qwen 3B-14B parameters):
- Without memory: ~54% AVG@4
- With REM: ~63% AVG@4 (a gain of over 9 percentage points)
The Major Discovery: Memory Quality Substitutes for Model Scale
The most profound finding is the memory scaling effect: a smaller model equipped with REM’s sophisticated memory can outperform a much larger model without it.
- Comparison 1: Qwen 3B-8B + REM (55.03% AVG@4) vs. Qwen 3B-14B without memory (54.65% AVG@4). The smaller model with advanced memory wins.
- Comparison 2: Qwen 3B-14B + REM (63.71% AVG@4) vs. Qwen 3B-32B without memory (61.00% AVG@4). The medium model with advanced memory wins.
Business Implications: This discovery has immense practical implications. It means businesses can achieve comparable or superior performance using smaller, less expensive models, leading to significant cost savings on API usage and infrastructure, all while potentially boosting performance.
Critical Ablations (Understanding What Matters)
Ablation studies help determine which components of a system are critical. By selectively disabling parts of REM and observing the impact, researchers identified key performance drivers.
Granularity of Extraction:
- Trajectory-Level Storage: Storing complete trajectories (all raw logs) resulted in a gain of only +2.67%.
- Keypoint-Level Extraction: Extracting only crucial keypoints (e.g.,
get_stock_info,place_orderfrom the stock trading example) led to a much higher gain of +4.17%.
This shows that concise, targeted information extraction is far more effective than raw data dumps. Providing an LLM with overly detailed, unfiltered instructions can lead to “noise” and even steer it towards deterministic, less adaptive outcomes. A shorter, more surgical approach to instructions, focusing on key elements, enhances probabilistic reasoning and accuracy.
Implementing the REM Framework
The REM framework is available as a Python library (pip install rem-ai) for developers building AI agents from scratch. It’s a modular framework that integrates persistent memory types:
- Personal Memory: For individual preferences.
- Task Memory: For specific task-related knowledge.
- Tool Memory: For tool usage knowledge.
- Working Memory: For short-term, context-specific information.
It can be used with agent frameworks like AgentScope and supports various backends for storage, including Elasticsearch and ChromeDB, or local storage.
Conclusion
The REM framework represents a significant leap forward in AI agent design, addressing the critical challenge of dynamic, intelligent memory management. By enabling agents to learn from errors, adapt to new contexts, and refine their knowledge base continuously, REM moves us closer to AI that exhibits human-like learning capabilities. This research underscores the importance of sophisticated memory systems for boosting AI performance, scalability, and cost-effectiveness, proving that quality memory can often be more impactful than raw model size.
🔍 Discover Kaptan Data Solutions — your partner for medical-physics data science & QA!
We're a French startup dedicated to building innovative web applications for medical physics, and quality assurance (QA).
Our mission: provide hospitals, cancer centers and dosimetry labs with powerful, intuitive and compliant tools that streamline beam-data acquisition, analysis and reporting.
🌐 Explore all our medical-physics services and tech updates
💻 Test our ready-to-use QA dashboards online
Our expertise covers:
🔬 Patient-specific dosimetry and image QA (EPID, portal dosimetry)
📈 Statistical Process Control (SPC) & anomaly detection for beam data
🤖 Automated QA workflows with n8n + AI agents (predictive maintenance)
📑 DICOM-RT / HL7 compliant reporting and audit trails
Leveraging advanced Python analytics and n8n orchestration, we help physicists automate routine QA, detect drifts early and generate regulatory-ready PDFs in one click.
Ready to boost treatment quality and uptime? Let’s discuss your linac challenges and design a tailor-made solution!
Get in touch to discuss your specific requirements and discover how our tailor-made solutions can help you unlock the value of your data, make informed decisions, and boost operational performance!
Comments