In the rapidly evolving landscape of healthcare, Artificial Intelligence (AI) and Machine Learning (ML) are becoming indispensable tools, especially in specialized fields like medical physics. This article aims to demystify machine learning, clarify its essential concepts, and illustrate its significant impact and practical applications within medical physics.
What is Machine Learning?
Machine Learning is a subset of Artificial Intelligence (AI) that enables systems to learn from data, identify patterns, and make decisions with minimal human intervention. Unlike traditional programming, where rules are explicitly coded, ML models improve their performance on a specific task through experience, often by processing vast amounts of data. Deep Learning, a further subset of ML, utilizes neural networks inspired by the human brain to tackle even more complex problems, such as image segmentation and knowledge-based planning.
Why Machine Learning Now?
The surge in ML’s relevance is due to several converging factors:
- Abundant Data: The digital age generates unprecedented volumes of data.
- Storage Capabilities: Advanced storage solutions can house this massive data.
- Powerful Computing: GPUs and cloud computing offer the necessary processing power.
- Ubiquitous Devices: Sensors and internet-connected devices continuously feed new data.
When to Use Machine Learning
ML excels in scenarios where:
- Human expertise is limited or non-existent (e.g., navigating Mars via robots).
- Humans struggle to articulate or formalize expertise (e.g., speech recognition).
- Models need to be highly customized (e.g., personalized medicine).
- Large datasets are available for pattern recognition and analysis (e.g., genomics).
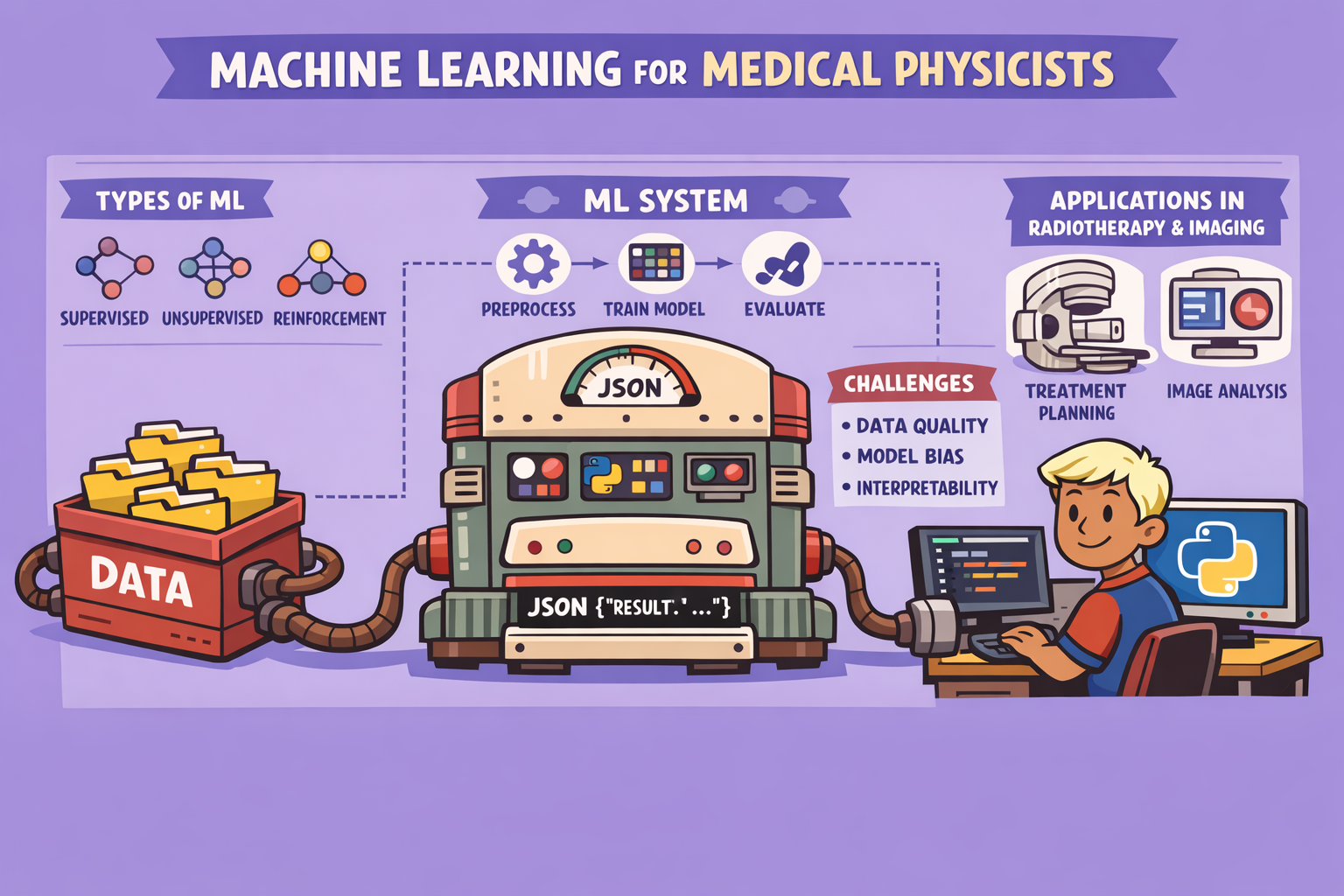
Types of Machine Learning
Machine learning can be broadly categorized into three main types:
- Supervised Learning:
- Concept: The model learns from labeled data, meaning both the input (questions) and desired output (answers) are provided. It then tries to generalize this learning to new, unseen data.
- Applications:
- Classification: Categorizing data into distinct classes (e.g., identifying spam emails, distinguishing between benign and malignant tumors, classifying medical images as cat or dog).
- Regression: Predicting a continuous output value (e.g., forecasting stock prices, predicting temperature, determining the market value of a house based on features).
- Key Requirement: Labeled training data.
- Unsupervised Learning:
- Concept: The model explores unlabeled data to find hidden patterns or intrinsic structures within it without explicit guidance. It’s about finding relationships and anomalies.
- Applications:
- Clustering: Grouping similar data points together (e.g., segmenting an image into different regions, grouping patients with similar genetic profiles).
- Anomaly Detection: Identifying unusual or unexpected data points (e.g., detecting fraud, identifying unusual activity in patient monitoring).
- Pattern Recognition: Discovering recurring patterns in complex datasets.
- Key Requirement: No pre-existing labels for the data.
- Reinforcement Learning:
- Concept: The model learns by performing actions in an environment and receiving rewards for desired behaviors and penalties for undesirable ones. It’s like training through trial and error.
- Applications:
- Gaming: AI agents learning to play games (e.g., the famous Mario game where positive actions lead to rewards).
- Robotics: Training robots to perform tasks through optimal decision-making.
- Autonomous Systems: Developing self-driving cars that learn from environmental interactions.
- Key Requirement: A well-defined reward system and an interactive environment.
The Machine Learning Workflow: A Step-by-Step Guide
The process of building and deploying a machine learning model involves several critical steps:
- Data Gathering:
- Objective: Collect relevant data based on the problem at hand.
- Considerations: Data quantity and quality are paramount. For example, in radiotherapy, segmentation tasks may require hundreds of CT scans with corresponding structure sets. Manual labeling often requires domain expertise (e.g., oncologists for RT structures).
- Principle: More, high-quality data leads to better model performance.
- Data Processing:
- Objective: Clean and prepare the raw data for model training. This is often the most challenging and time-consuming step.
- Tasks:
- Dimension Consistency: Ensure all data has uniform dimensions.
- Handling Missing Data: Address any gaps or missing values (e.g., missing CT scans).
- Outlier Detection: Identify and manage data points that deviate significantly from the norm.
- Encoding Issues: Correct any improper data formatting or encoding.
- Impact: Clean data is crucial for accurate model performance; “garbage in, garbage out.”
- Feature Engineering:
- Objective: Extract meaningful features from the processed data that are most relevant to the problem. This reduces noise and focuses the model on critical information.
- Example: For CT scans, cropping images to remove unnecessary background and focusing only on the region of interest (e.g., tumor area) reduces dimensionality and computational load.
- Considerations: More features can lead to higher computational requirements (GPUs, memory). Over-engineering features can also introduce complexity.
- Algorithm Selection and Training:
- Objective: Choose an appropriate ML algorithm based on the problem type (supervised, unsupervised, reinforcement) and train the model using the prepared data.
- Algorithm Types: A wide array of algorithms exists, from simple linear models to complex neural networks (e.g., TensorFlow, PyTorch).
- Process: The model learns patterns and relationships from the data during training.
- Prediction and Evaluation:
- Objective: Use the trained model to make predictions on unseen data and evaluate its performance against desired metrics.
- Process:
- Prediction: Apply the model to new data to generate outputs.
- Evaluation: Assess metrics like accuracy, precision, recall, F1-score for classification, or R-squared, Mean Absolute Error (MAE) for regression problems.
- Hyperparameter Tuning: Adjust internal parameters of the model (hyperparameters) to optimize performance. This iterative process continues until satisfactory accuracy is achieved.
Core Principles and Challenges
Occam’s Razor Principle: In problem-solving, the simplest explanation requiring the fewest assumptions is often the best. However, in ML, there’s often a conflict between simplicity and accuracy, with more complex models often yielding higher accuracy.
No Free Lunch Theorem: No single ML algorithm is universally superior. An algorithm’s effectiveness depends heavily on the specific problem and data distribution. This necessitates continuous research and development of new algorithms tailored to particular challenges.
Curse of Dimensionality: Learning from high-dimensional data (data with many features) requires exponentially more data and computational resources. This can lead to reduced predictive power. Countermeasures include dimensionality reduction techniques like cropping images to focus on the region of interest.
Machine Learning in Medical Physics: Impact and Applications
ML is transforming medical physics by offering significant clinical, research, and efficiency improvements:
Clinical Impact:
- Improved Accuracy and Consistency:
- Auto-segmentation: Automated segmentation of target volumes (PTVs) and organs-at-risk, reducing variability and saving time.
- Automated Planning: AI-driven treatment planning, predicting dose distributions, and optimizing treatment delivery.
- Imaging: Noise reduction in CT/MRI, enhancing image reconstruction, and aiding tumor detection.
- Enhanced Patient Safety:
- Quality Assurance (QA): Predictive analytics for Linac QA, adaptive radiotherapy, and real-time monitoring to detect anomalies.
- Personalized Medicine: Patient-specific dose adaptations and treatment strategies based on individual characteristics.
Research and Efficiency:
- Time Savings: Automation of routine tasks (e.g., segmentation from hours to minutes).
- Big Data Utilization: Analyzing large datasets (log files, daily QA, patient images) to uncover hidden patterns and predict machine behavior.
- Faster Workflows: Streamlined clinical operations, smarter decision-making, and powerful research capabilities.
Tools and Platforms
- Programming Languages: Python (with libraries like NumPy, Pandas, Matplotlib for data handling; TensorFlow, PyTorch for deep learning) is prevalent. MATLAB is also used but is more expensive.
- Medical Imaging Specific Tools: Libraries like
pydicomand OpenCV are crucial. - Collaboration and Cloud Platforms: Jupyter Notebook, Google Colaboratory (Colab), GitHub, Google Cloud, and AWS facilitate development and collaboration.
- Clinical Integration: Plugins for Treatment Planning Systems (TPS) like Eclipse scripting, integrate AI tools and automate QA processes.
Learning Roadmap
Two common approaches for learning ML exist:
- Foundational Approach:
- Start with basic Python and core ML libraries.
- Advance to specialized courses in deep learning and medical image analysis.
- Identify a clinical problem, develop an ML pipeline, and validate results.
- Time Commitment: Minimum one year, with significant time spent on coursework.
- Problem-Driven Approach (Highly Recommended for Medical Physicists):
- Identify a real clinical problem.
- Review existing code and solutions available in the community.
- Crucially, apply your physics and domain knowledge to tune hyperparameters and improve performance. This is where a medical physicist’s expertise is invaluable, moving beyond simple copy-pasting to true innovation.
- Train the model and implement the results.
- Benefit: Saves significant time, allowing focus on model improvement rather than coding from scratch.
Common Myths and Best Practices
Myths:
- ML will replace medical physicists: No, ML is a tool to support decision-making, not a replacement.
- More data always guarantees better results: Quality of data is more important than quantity.
- Complex models are always superior: Simple models can often perform better for specific problems.
- ML is magic: It requires rigorous validation and understanding.
- A trained model works forever: Models need continuous monitoring, updating, and re-training for different patient populations or regions.
Best Practices:
- Define clear clinical objectives.
- Ensure high-quality, properly labeled data.
- Train, validate, and test models thoroughly.
- Avoid overfitting.
- Interpret models with physics understanding.
- Document and reproduce results.
- Validate models with external, diverse datasets to ensure generalizability.
Commissioning and Validation of AI Tools
As AI tools become medical devices, their commissioning and validation become critical. This will involve:
- Clinical Validation: Cross-checking AI outputs (e.g., auto-segmentation) against expert human input (e.g., oncologists).
- Inter-institutional Validation: Testing models trained at one institution on data from other institutions with different protocols and scanner types.
- Uncertainty Quantification: Defining the uncertainties and correlations associated with AI predictions.
- Regulatory Compliance: Addressing regulatory and ethical approvals for AI-driven clinical tools.
The role of medical physicists will evolve from purely operational tasks to being crucial in validating, commissioning, and ensuring the safe and effective integration of AI into clinical practice. They will be the bridge between complex AI technologies and practical patient care.
Conclusion
Machine learning offers transformative potential for medical physics, enhancing accuracy, efficiency, and patient safety. By understanding its fundamentals, embracing best practices, and applying domain expertise, medical physicists can effectively leverage these powerful tools to push the boundaries of healthcare.
🔍 Discover Kaptan Data Solutions — your partner for medical-physics data science & QA!
We're a French startup dedicated to building innovative web applications for medical physics, and quality assurance (QA).
Our mission: provide hospitals, cancer centers and dosimetry labs with powerful, intuitive and compliant tools that streamline beam-data acquisition, analysis and reporting.
🌐 Explore all our medical-physics services and tech updates
💻 Test our ready-to-use QA dashboards online
Our expertise covers:
🔬 Patient-specific dosimetry and image QA (EPID, portal dosimetry)
📈 Statistical Process Control (SPC) & anomaly detection for beam data
🤖 Automated QA workflows with n8n + AI agents (predictive maintenance)
📑 DICOM-RT / HL7 compliant reporting and audit trails
Leveraging advanced Python analytics and n8n orchestration, we help physicists automate routine QA, detect drifts early and generate regulatory-ready PDFs in one click.
Ready to boost treatment quality and uptime? Let’s discuss your linac challenges and design a tailor-made solution!
Get in touch to discuss your specific requirements and discover how our tailor-made solutions can help you unlock the value of your data, make informed decisions, and boost operational performance!
Comments