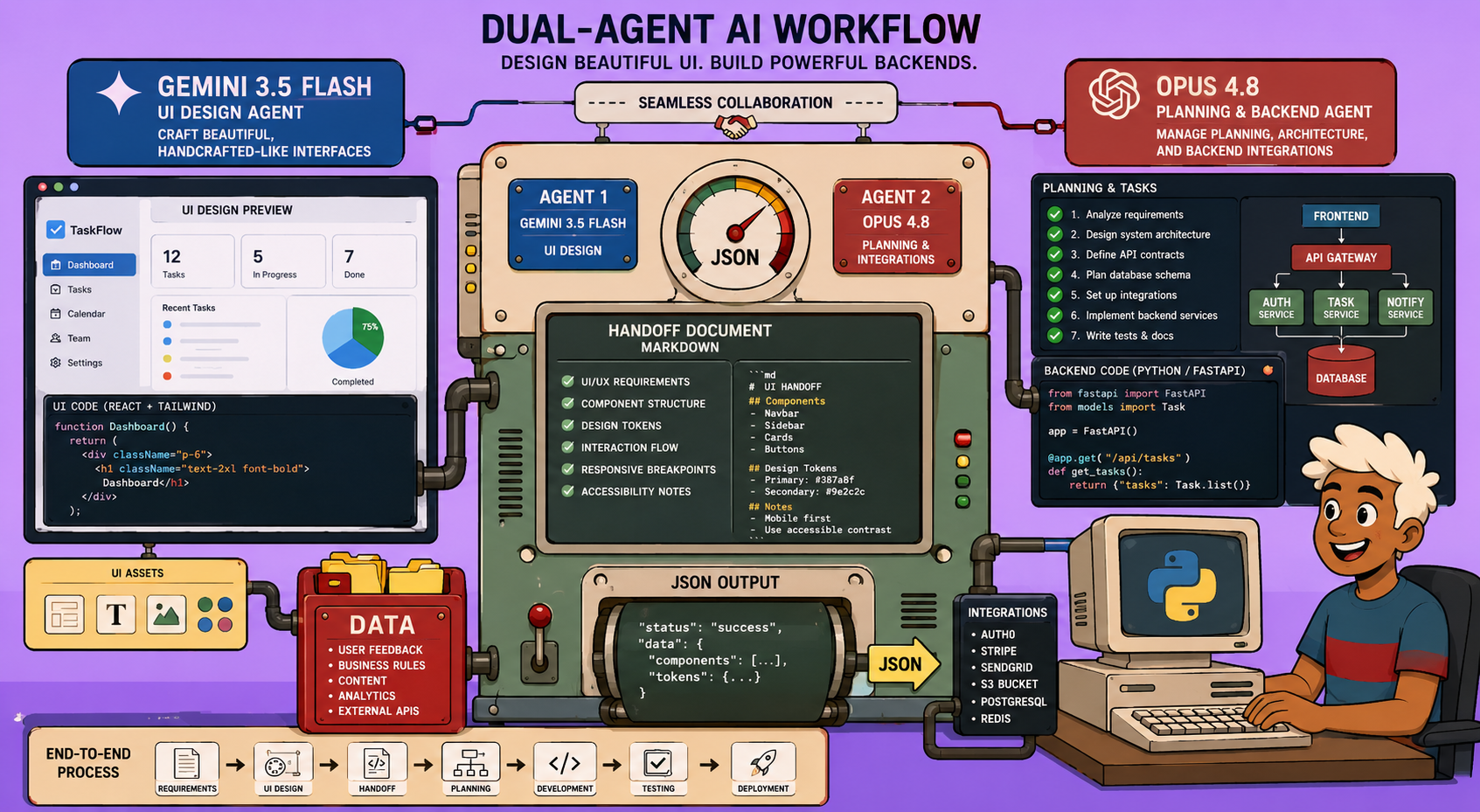
The landscape of AI-driven coding is rapidly evolving, with new Large Language Models (LLMs) constantly pushing the boundaries of what’s possible. Recently, Google introduced Gemini 3.5 Flash, an LLM noted for its speed, cost-effectiveness, and surprisingly adept ability to craft aesthetically pleasing user interfaces. Hot on its heels, Anthropic released Opus 4.8, a model celebrated for its superior reasoning capabilities, particularly in complex, longer-running agentic engineering tasks.
Rather than choosing one over the other, a powerful new workflow leverages the strengths of both. This innovative approach combines Gemini 3.5 Flash for designing captivating front-ends with Opus 4.8 for intelligent planning, content generation, and intricate backend integrations, enabling the creation of beautiful, full-stack web applications.
The Hybrid AI Coding Workflow: A Detailed Breakdown
This workflow is structured as a series of distinct coding agent sessions, each managed by a specific LLM, and communicating through “handoff documents.” This modularity allows for optimal resource allocation, cost efficiency, and enhanced experimentation.
High-Level Workflow Overview
The core idea is to break down the web application development process into specialized steps. Each step is a separate coding agent session, and the agents communicate by passing markdown handoff documents.
- Initial Exploration (Sonnet/Gemini): Survey the repository and the application specification.
- Planning (Opus): Develop a comprehensive plan based on the exploration, focusing on content, integrations, and deployment.
- UI Design (Gemini 3.5 Flash): Build the user interface based on the planning, specializing in visual aesthetics.
- Integrations (Opus): Implement backend logic, APIs, and database structures.
- Validation (Sonnet/Opus): Run tests, linting, and fix any issues.
- Deployment (Opus): Automate the deployment process.
- Smoke Testing (Opus with Agent Browser Skill): Verify the deployed application’s functionality from a user’s perspective.
Step-by-Step How-To Guide
To implement this workflow, you’ll need a coding agent harness like Pi or Anti-Gravity, and access to the specified LLMs (via platforms like OpenRouter). The repository for this workflow often includes a README with setup instructions and necessary skills.
Prerequisites:
- Coding Agent Harness: Pi or Anti-Gravity (or a similar tool that allows for skill invocation and model switching).
- LLM Access: Configure OpenRouter for access to Gemini 3.5 Flash, Opus 4.8, and Sonnet.
- Workflow Skills: Download the provided skills from the GitHub repository.
The Workflow in Action:
Step 1: Input and Initial Exploration
- Input: A detailed
spec.mddocument outlining the full-stack application you wish to create. This can be crafted manually or with the help of a coding agent.- Example Spec: The
spec.mdfor a “Deep Space Catalog” application would detail its features, data, and user interactions.
- Example Spec: The
- Skill Invocation: Use a more token-efficient model like Sonnet for initial exploration.
- Command (in Cloud Code/Pi):
model /model Sonnet(if not already default) - Command:
front-end mix explorer [path/to/spec.md]
- Command (in Cloud Code/Pi):
- Output:
context.md. This document summarizes the initial exploration, including repo state (greenfield or existing template), framework recommendations, brand assets, environment variables, and data layer considerations. This pre-analysis helps the planning phase start efficiently without excessive token use by Opus.
Step 2: Comprehensive Planning
- Input: The
context.mdgenerated from the exploration phase. - Model: Opus 4.8 (for its superior reasoning).
- Command (in Cloud Code/Pi):
model /model Opus
- Command (in Cloud Code/Pi):
- Skill Invocation:
front-end mix plan [path/to/context.md] - Output:
plan.md. This detailed plan is structured into three key sections:- Section A: Site Content and Intent: Describes the voice, mood, and messaging. Crucially, it avoids UI structure details, deferring this to Gemini.
- Section B: Integration Scope: Outlines backend APIs, database models (e.g., for planets in a catalog), and authentication needs.
- Section C: Deployment Plan: Specifies how the application will be deployed (e.g., to Vercel, DigitalOcean).
Step 3: UI Design (with Gemini 3.5 Flash)
- Input: The
plan.mdfrom the planning phase, specifically focusing on Section A. - Model: Gemini 3.5 Flash (for its UI generation capabilities).
- Command (in Pi/Anti-Gravity):
model /model Gemini 3.5 Flash
- Command (in Pi/Anti-Gravity):
- Skill Invocation:
front-end mix design [path/to/plan.md]- Note: If your coding agent doesn’t support direct skill invocation, you can instruct it to “read the instructions from [path/to/skill]” and then provide the plan path.
- Output: The user interface code and a
UI_summary.md. Gemini excels here, creating visually appealing front-ends that often appear human-crafted, avoiding the common “LLM look.” This step focuses solely on the UI, using the detailed content and messaging from the plan.
Step 4: Integrations, Validation, Deployment, and Smoke Testing
- Integrations (Opus): Based on
plan.md(Section B) andUI_summary.md, Opus builds out the backend, APIs, and connects the frontend to the data layer.- Skill Invocation: (e.g.,
front-end mix integrate [path/to/plan.md] [path/to/UI_summary.md])
- Skill Invocation: (e.g.,
- Validation (Sonnet/Opus): The agent runs unit tests, linting, and other quality checks. Opus is used to debug and fix any identified issues.
- Skill Invocation: (e.g.,
front-end mix validate [path/to/codebase])
- Skill Invocation: (e.g.,
- Deployment (Opus): Following
plan.md(Section C), Opus automates the deployment to the specified platform.- Skill Invocation: (e.g.,
front-end mix deploy [path/to/codebase])
- Skill Invocation: (e.g.,
- Smoke Testing (Opus with Agent Browser Skill): The agent uses browser automation to interact with the deployed application as a user would, verifying core functionality and user experience.
- Skill Invocation: (e.g.,
front-end mix smoketest [deployed_app_url])
- Skill Invocation: (e.g.,
- Output: A fully deployed, functional web application.
Key Takeaways & Best Practices
- Modular Design: Breaking tasks into single-focus steps prevents LLMs from getting overwhelmed and improves overall output quality, especially for complex applications.
- Handoff Documents: Using markdown documents for communication between steps is crucial. This creates explicit interfaces between LLM sessions, making the workflow robust and debuggable.
- Strategic Model Selection: Leverage each LLM’s unique strengths:
- Gemini 3.5 Flash: Cost-effective, fast, and excellent for UI generation.
- Opus 4.8: Superior reasoning for complex planning, content accuracy (page copy), and backend integrations.
- Sonnet: Efficient for initial exploration and simpler validation tasks.
- Cost Optimization: By using cheaper models for specific tasks (like Gemini for UI and Sonnet for exploration), you can significantly reduce token costs while maintaining high-quality results where it matters most.
- Human-in-the-Loop: At each handoff, you can review the generated document or code to ensure the agent is on track, allowing for intervention and course correction if needed.
- Experimentation: The modular nature of this workflow makes it easy to swap out models for different steps, allowing you to experiment and find the optimal combination for your specific needs.
This hybrid approach allows developers to build impressive proof-of-concepts and MVPs for full-stack applications with remarkable speed and quality, showcasing the power of combining specialized AI models.
🔍 Discover Kaptan Data Solutions — your partner for medical-physics data science & QA!
We're a French startup dedicated to building innovative web applications for medical physics, and quality assurance (QA).
Our mission: provide hospitals, cancer centers and dosimetry labs with powerful, intuitive and compliant tools that streamline beam-data acquisition, analysis and reporting.
🌐 Explorez tous nos services et actualités tech
💻 Testez nos dashboards QA en ligne
Notre SaaS de physique médicale arrive bientôt — conçu pour la radiothérapie, l'imagerie et la médecine nucléaire.
Our expertise covers:
🔬 Patient-specific dosimetry and image QA (EPID, portal dosimetry)
📈 Statistical Process Control (SPC) & anomaly detection for beam data
🤖 Automated QA workflows with n8n + AI agents (predictive maintenance)
📑 DICOM-RT / HL7 compliant reporting and audit trails
Leveraging advanced Python analytics and n8n orchestration, we help physicists automate routine QA, detect drifts early and generate regulatory-ready PDFs in one click.
Ready to boost treatment quality and uptime? Let’s discuss your linac challenges and design a tailor-made solution!
Get in touch to discuss your specific requirements and discover how our tailor-made solutions can help you unlock the value of your data, make informed decisions, and boost operational performance!
Comments