The landscape of AI is constantly evolving, with new innovations emerging every week. One of the most significant recent trends, highlighted by experts like Andre Karpathy, is the development of robust LLM knowledge bases. While many solutions focus on integrating external information, this article delves into a personalized system designed to provide internal memory for AI agents, specifically for codebases, offering a simpler yet highly effective approach.
The Compiler Analogy for Knowledge Management
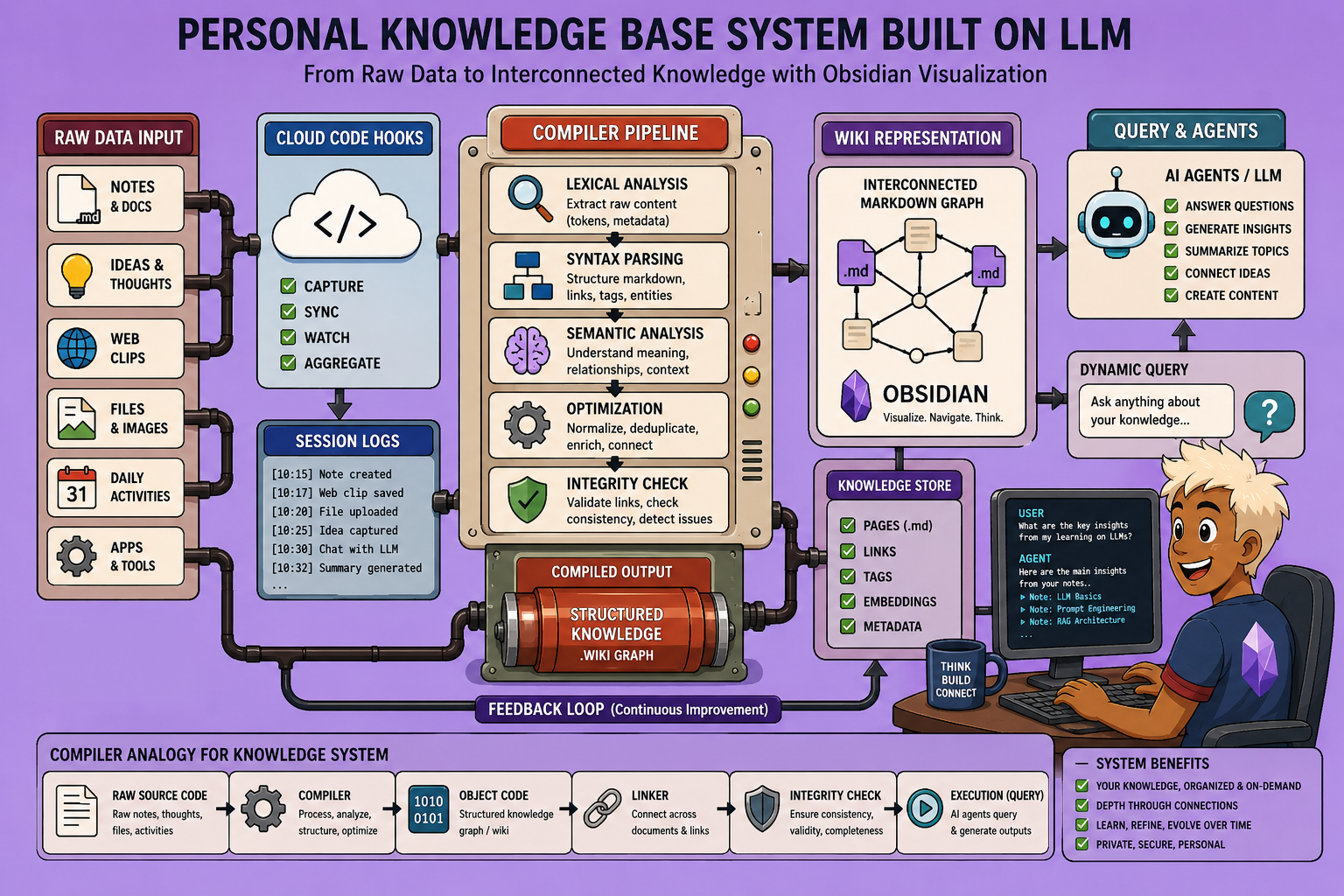
To understand this system, we can draw a powerful analogy to software compilation. Just as a compiler transforms raw source code into an executable application, our knowledge base processes raw information into an organized, queryable wiki.
- Source Code (Raw Data): This is the entry point for all information. For external data, this could be articles, documents, or online content. In our internal system, it comprises session logs—transcripts of conversations with our coding agent or “second brain.” All raw data is dumped into a designated “raw folder” in plain Markdown format.
- Compilation Step (LLM Processing): This is where a large language model (LLM) processes the raw data. Its role is to generate summaries, identify connections between documents, and structure the knowledge. For Karpathy’s external system, this involves scripts that feed raw information to an LLM to produce a wiki. Our internal system uses a similar process, but for session logs.
- Executable File (The Wiki): This is the compiled version of our knowledge, intended for an agent to query. It’s often referred to as a “wiki,” containing compiled articles, backlinks (showing connections between knowledge fragments), and an index. Obsidian, with its graph view, is particularly useful here, allowing us to visualize how different pieces of knowledge are interconnected, facilitating more efficient searches and comprehensive answers from our agent.
- Test Suite (Linting & Health Checks): Before execution, just like code, our knowledge base undergoes “linting” or health checks. This involves identifying gaps in information, correcting outdated data, fixing broken links, and ensuring the overall integrity and accuracy of the knowledge base. This step is crucial for maintaining a reliable personal knowledge repository.
- Execution (Querying): This is the final stage where agents leverage the wiki to find information relevant to current tasks. A key insight from Karpathy is that the LLM performs remarkably well at automatically maintaining index files. This means no sophisticated semantic search or vector databases are needed; the agent can simply navigate the indexed files within the Obsidian vault, making the system simple yet powerful.
Data Flow and Implementation for Internal Data
While the compiler analogy explains the high-level architecture, the specific data flow is crucial for implementation, especially when adapting it for internal data.
- External Information Ingestion (Karpathy’s Approach): Karpathy’s setup primarily uses tools like Obsidian Web Clipper to import external articles and web content directly into the “raw folder” of the Obsidian vault. This unprocessed Markdown is then fed to an LLM for compilation into the wiki.
- Example: A “raw folder” might contain various AI-related articles. The compiled “wiki” would then have a “concepts” folder, linking different ideas extracted from these documents, along with an “index” file guiding the agent on where to start searching based on a query.
- The
agents.mmdfile contains global rules describing the entire LLM knowledge base system to the agent, providing meta-reasoning about its environment and information sources (index, log file, etc.).
- Internal Information System (Our Custom Implementation): Inspired by Karpathy’s architecture, our system provides an evolving memory for “Code” through automated session log capture.
- Automated Session Capture: Instead of external data, we capture session logs automatically via hooks. These logs serve as our “raw folder,” recording conversations.
- Claude Agent SDK: The Claude Agent SDK processes these logs in the background, extracting information and transforming it into structured, referenced knowledge articles. This allows the coding agent to become increasingly intelligent over time by remembering past decisions and project evolution.
- Simplified Setup: The core strength of this system lies in its simplicity. By sending a specific prompt to the Claude agent, it can clone a repository and set up all necessary configurations with Code hooks, transforming itself into a personal knowledge base for internal information.
Step-by-Step Setup and Usage:
- Initialize Obsidian Vault:
- Install Obsidian (free and easy).
- Open a folder as a new vault, pointing it to your source code directory.
- (Optional) Customize the appearance by choosing a theme and switching to dark mode.
- Integrate with Code Claude:
- The system is entirely driven by Code Claude hooks. You don’t need to install additional integrations.
- In your
settings.jsonfile, define the hooks:session_starthook: This script runs at the beginning of each Code Claude session. It loads theagents.mmdfile (to inform Claude about its environment) and theindex.mmdfile (the continuously updated list of knowledge base files).pre_compactandsession_endhooks: These hooks are triggered when context is about to be lost (e.g., closing a session or memory compaction). They send the latest messages from Code Claude to another LLM to summarize the conversation. This summary is then written to the “daily logs” file, our equivalent of the raw data folder for internal information.
- Querying the Agent:
- Once setup, you can ask your agent questions about your codebase. The agent will leverage its knowledge base (the wiki and daily logs) to provide answers, even identifying specific articles it referenced.
- The “daily logs” act as the raw data, while the “wiki” contains the more formatted and linked information, complete with a graph view in Obsidian.
The Capitalization Loop: Continuous Learning
The beauty of this system lies in its continuous learning mechanism, or “capitalization loop”:
- Questioning: We start by posing questions, leveraging the knowledge base.
- Searching and Synthesizing: The agent searches through multiple wiki articles, synthesizes information, and provides an answer.
- Recording Insights: Crucially, the system records the connections made and the lessons learned from these interactions.
- Wiki Enrichment: These new insights, along with future Code Claude coding sessions, progressively enrich the wiki.
This process means that the more questions you ask, the more robust and intelligent your agent becomes. The system automatically processes new interactions: if you extend a conversation or perform further web research, the pre_compact or session_end hooks automatically summarize the new information and integrate it into your daily logs. Periodically, a “flush” process extracts concepts and connections from these logs, integrating them into the main wiki. This ensures that the agent’s answers become increasingly relevant over time, with minimal manual effort.
This approach offers a highly customizable and self-improving LLM knowledge base for internal data, leveraging the collaborative power of AI agents and structured knowledge management.
🔍 Discover Kaptan Data Solutions — your partner for medical-physics data science & QA!
We're a French startup dedicated to building innovative web applications for medical physics, and quality assurance (QA).
Our mission: provide hospitals, cancer centers and dosimetry labs with powerful, intuitive and compliant tools that streamline beam-data acquisition, analysis and reporting.
🌐 Explore all our medical-physics services and tech updates
💻 Test our ready-to-use QA dashboards online
Our medical physics SaaS is coming soon — designed for radiation therapy, imaging, and nuclear medicine centers.
Our expertise covers:
🔬 Patient-specific dosimetry and image QA (EPID, portal dosimetry)
📈 Statistical Process Control (SPC) & anomaly detection for beam data
🤖 Automated QA workflows with n8n + AI agents (predictive maintenance)
📑 DICOM-RT / HL7 compliant reporting and audit trails
Leveraging advanced Python analytics and n8n orchestration, we help physicists automate routine QA, detect drifts early and generate regulatory-ready PDFs in one click.
Ready to boost treatment quality and uptime? Let’s discuss your linac challenges and design a tailor-made solution!
Get in touch to discuss your specific requirements and discover how our tailor-made solutions can help you unlock the value of your data, make informed decisions, and boost operational performance!
Comments