The software development lifecycle (SDLC) is being rewritten. A comprehensive new guide, recently released, provides a masterclass on the entire AI-driven SDLC, distilling industry-converging best practices into a clear, actionable framework. This article breaks down the key concepts, explains how to build a robust “harness” for your AI coding assistant, and shows you how to move from unreliable “vibe coding” to systematic, repeatable agentic engineering.
The New Bottleneck: Specification Quality
The traditional SDLC is a linear process: requirements gathering, design, implementation (the bulk of the time), testing, review, deployment, and maintenance. With AI, the implementation phase—once the primary bottleneck—has collapsed from weeks to minutes or hours. The critical bottleneck has shifted to the beginning and end of the cycle.
The speed of the AI-driven SDLC is now determined by specification quality. The upfront work of gathering requirements and the final validation stages are still largely human-driven. This is why, despite claims of 10x engineer output, business-level productivity gains often appear smaller. The real opportunity lies in platforms and processes that accelerate requirements gathering and final validation, as the middle (implementation) is largely solved.
The AI Coding Spectrum: It’s Not Binary
AI coding isn’t a simple on/off switch. It’s a spectrum. The key is to choose the right level for the job, not to assume one size fits all.
| Level | Specification | Verification | Risk Profile |
|---|---|---|---|
| Vibe Coding | Casual, high-level natural language prompts | “Does it seem to work?” Minimal testing | High – Acceptable for disposable code or proofs of concept |
| Structured AI Assisted | More detailed prompts, but no formal workflow for specs or architecture docs | Manual spot-checking and more thorough manual testing | Medium – Good for MVPs |
| Agentic Engineering | Engineered, repeatable specifications. Specs are treated as code. | Automated tests, CI/CD gates, LLM judges, separate code review process | Low – The goal for reliable, production-grade software |
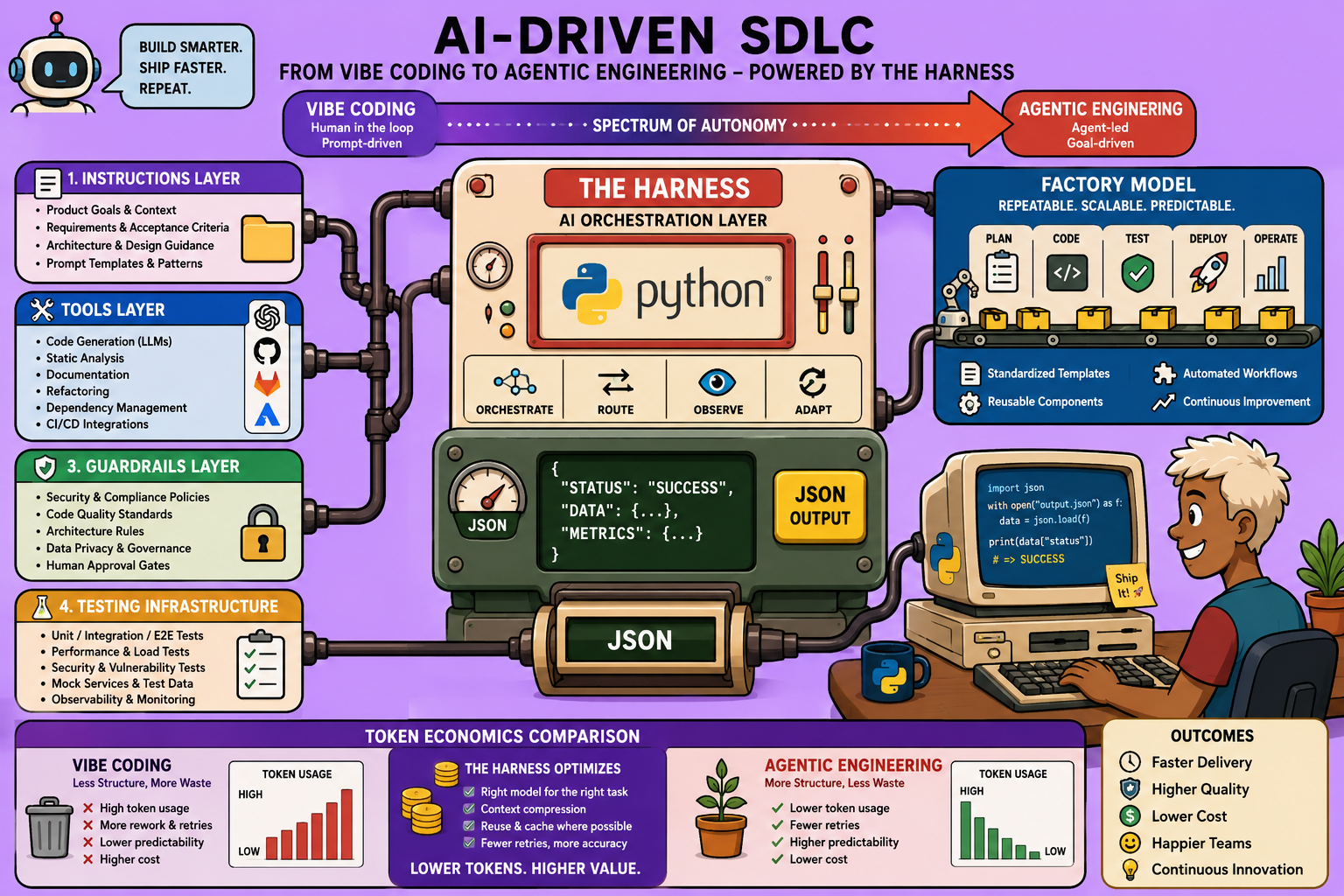
The 90% Solution: The Harness
The single most important concept is the harness. The large language model (LLM) that powers your AI coding assistant is only about 10% of the system. The remaining 90%—and the part you control—is the harness. As the guide states, “The agent is the model plus the harness.”
The harness is the set of context, rules, and workflows you bring to your AI coding assistant. It includes:
- Instructions and Rules: System prompts, coding conventions, and global rules.
- Tools and MCP Servers: Access to codebases, APIs, and external services.
- Guardrails and Hooks: Token limits, security policies, deterministic actions in the lifecycle.
- Skills: Workflows packaged into reusable units (e.g., a “planning agent” skill, a “code reviewer” skill).
- Testing Infrastructure: Evals and automated tests for the agent to iterate.
- Observability and Tracing: Monitoring agent behavior and output in production.
A powerful example of the harness’s impact is that a model ranked outside the top 30 on a benchmark like SWE-bench can be pushed into the top five simply by providing a superior set of rules and workflows.
The Factory Model: A Repeatable Workflow
Agentic engineering operates on a “factory” model. Instead of you writing code, you design the system and the harness. The agent then produces the code and documentation. This is a higher upfront investment than vibe coding, but it yields a repeatable, scalable process.
The workflow is as follows:
- Define: You define the specs, context, and requirements.
- Plan: A dedicated planning agent creates a detailed plan for the feature or bug fix. This is a separate session to avoid polluting the main coding context.
- Build: The plan is passed to a coding agent, which operates within the guardrails and sandbox you’ve defined.
- Iterate: The coding agent runs its tests and evals, iterating autonomously to improve its output.
- Review: You review the final output (e.g., via a pull request) before it proceeds to deployment.
Critical component: The workflow splits the planning and coding into separate agents or sessions. This prevents “context rot” and bias.
System Evolution: The Key to Long-Term Success
The harness itself must evolve. Adopt a system evolution mindset. When your AI coding assistant produces suboptimal output or requires excessive hand-holding, don’t just fix the bug. Ask the agent to perform a retrospective and identify improvements to the harness—your rules, workflows, or guardrails. This ensures that every iteration makes the system more reliable.
Static vs. Dynamic Context
Context is your most precious resource. LLMs suffer from context rot just like humans.
- Static Context (loaded every session): Rules, core guardrails, system prompt. It’s reliable but expensive (fills the context window).
- Dynamic Context (loaded on demand): Agent skills, RAG results, codebase conventions. It’s efficient but carries a risk that the agent may not seek it out when needed.
The industry is converging on a single, generalist agent that dynamically loads specialized skills (workflows) to become a planner, a reviewer, or a coder. This is far more effective than complex multi-agent systems.
Conductor vs. Orchestrator
The guide introduces two modes of interaction with AI coding assistants:
- Conductor: Micromanaging the AI, guiding it file-by-file. This is useful for deep debugging or initial exploration but is a sign of an immature harness.
- Orchestrator: Delegating large, multi-file tasks to agents and reviewing outcomes. This is the goal for agentic engineering.
The guide suggests moving between both modes, but the ideal is to always operate as an orchestrator once the harness is reliable.
Token Economics: The Case for Upfront Investment
Vibe coding has low upfront costs (low capital expenditure) but extremely high operational expenditure (burning millions of tokens iterating on slop code).
Agentic engineering requires high upfront capital expenditure (time to design the harness) but delivers low operational expenditure. The crossover point is reached quickly, making agentic engineering 3 to 10 times more reliable and cheaper in the long run. The harness is an engineered resource that lives in version control, just like the code itself.
🔍 Discover Kaptan Data Solutions — your partner for medical-physics data science & QA!
We're a French startup dedicated to building innovative web applications for medical physics, and quality assurance (QA).
Our mission: provide hospitals, cancer centers and dosimetry labs with powerful, intuitive and compliant tools that streamline beam-data acquisition, analysis and reporting.
🌐 Explore all our medical-physics services and tech updates
💻 Test our ready-to-use QA dashboards online
Our expertise covers:
🔬 Patient-specific dosimetry and image QA (EPID, portal dosimetry)
📈 Statistical Process Control (SPC) & anomaly detection for beam data
🤖 Automated QA workflows with n8n + AI agents (predictive maintenance)
📑 DICOM-RT / HL7 compliant reporting and audit trails
Leveraging advanced Python analytics and n8n orchestration, we help physicists automate routine QA, detect drifts early and generate regulatory-ready PDFs in one click.
Ready to boost treatment quality and uptime? Let’s discuss your linac challenges and design a tailor-made solution!
Get in touch to discuss your specific requirements and discover how our tailor-made solutions can help you unlock the value of your data, make informed decisions, and boost operational performance!
Comments